
As a motivating example, we can consider a signal recognition task on an automated vehicle. The vehicle driving on the road needs to recognize the traffic signal ahead through real-time image recognition. We can consider a simple vehicle configuration equipped with two cameras generating different real-world image samples and two machine learning modules for image classifiers.
There are three possible architectures under this configuration with respect to the combinations of machine learning models and input data sources.
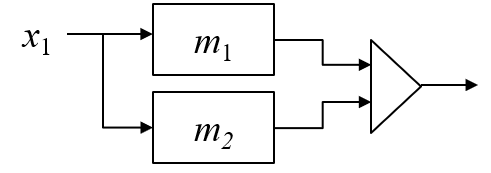 This architecture employs two machine learning models but apply the same input data. The system outputs error when both machine learning models output errors for the same input data.
This architecture employs two machine learning models but apply the same input data. The system outputs error when both machine learning models output errors for the same input data.
 This architecture deploys the same machine learning model to two machine learning modules that receives input data from different sources. The system outputs error when both modules' outputs are errors.
This architecture deploys the same machine learning model to two machine learning modules that receives input data from different sources. The system outputs error when both modules' outputs are errors.
 This architecture employs two machine learning models and apply different input data to individual machine learning modules. The system outputs error when both machine learning models output errors for the individual input data.
This architecture employs two machine learning models and apply different input data to individual machine learning modules. The system outputs error when both machine learning models output errors for the individual input data.
It is not entirely trivial to choose the most reliable architecture under given models and input data sources. The reliability of system outputs depends on how error characteristics are correlated among machine learning models and different input data sets. To quantitatively analyze the architecture capabilities, we introduce diversity measures and formulate the architecture reliabilities through diversity measures.
For more details of our preliminary reliability models, you can learn from:
We believe that diversity is the key factor for improving system reliability by N-version machine learning approaches. There are a number of approaches to diversify the outputs of machine learning modules. Like traditional N-version programming, we can employ different algorithms, programming codes, and software libraries to build diverse versions of modules. For machine learning systems, we can also use different training data sets, training procedures, and parameters for generating different versions. By combining the outputs from the obtained diverse machine learning modules, the probability of mutual output errors can be reduced significantly.
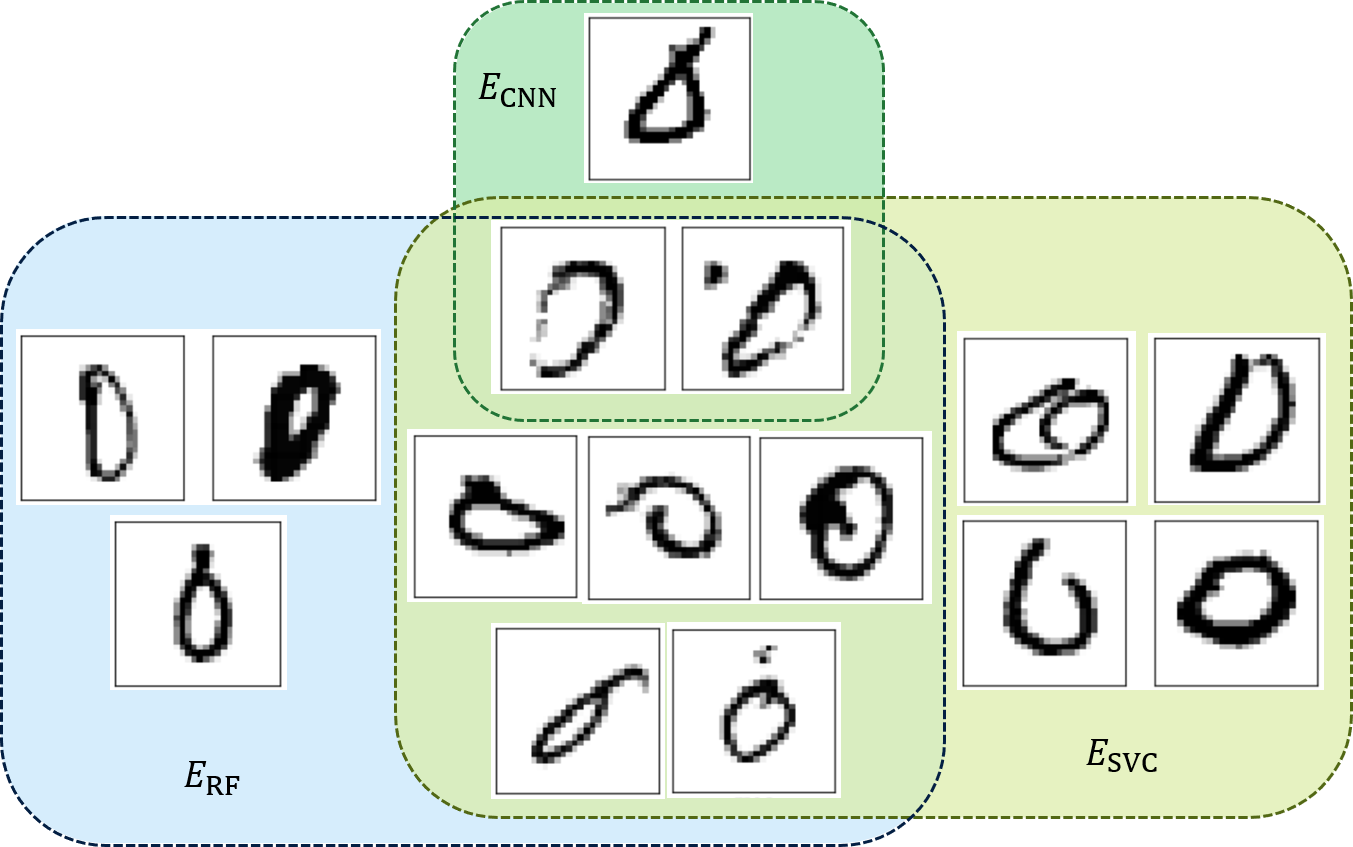
In the above example, three different machine learning models (Random Forest, Support Vector Classifier, and CNN) are independently used to classify the hand-written digits labeled "0". The samples that cannot be classified correctly are depicted. For example, three samples in ECNN are the samples that cannot be classified correctly by CNN. We can see that only two out of 980 test samples cannot be classified correctly by either one of the models.
A similar benefit can be obtained even using a single version machine learning model by diversifying input data at inference.
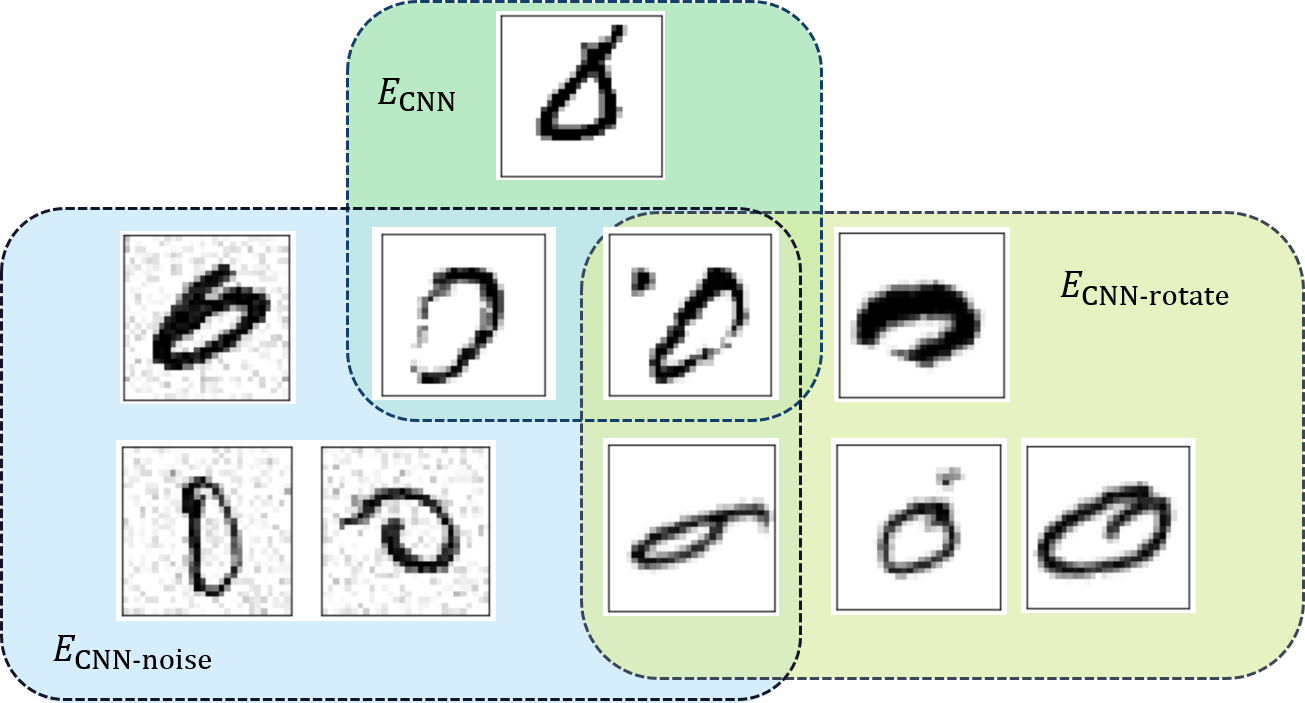
In the above example, we use the same CNN but apply different input perturbations to the input data. ECNN-noise represents the set of samples that cannot be correctly classified after adding noise to the original input data. On the other hand, ECNN-rotate shows the set of samples that cannot be correctly classified after slightly rotating the original input data. As a result, we can see that only one sample out of 980 test samples encounters mutual errors. In other words, even with a single CNN, we can potentially improve the reliability of system output by obtaining different outputs from perturbated input data. This approach is considerably cost-efficient compared to building and operating different machine learning models simultaneously for N-version configuration.
For more details about our experimental findings, please also see our paper:
Last update: 2023.10.29